В мае 2011 года, в расширенном докладе Майкла Рубина (Michael Rubin), занимающегося системами хранения данных в Google (и ответственный в первую очередь за их развитие и масштабирование), прозвучал подробный сравнительный обзор современных файловых систем, в котором, кроме перечисления их преимуществ и недостатков, были даны и некоторые прогнозы о будущем развитии и потребностях информационной индустрии
в этой сфере.

В частности, была рассмотрена способность существующих файловых систем (ФС) адаптироваться к вызовам уже ближайшего будущего, в связи с чем, из всех были выделены четыре ведущие файловые системы «новой школы», изначально спроектированные с учетом удовлетворения самых взыскательных требований и запросов.
Майкл Рубин отдельно подчеркнул, что Google умышленно не рассматривал среди числа этих перспективных ФС, такие некогда популярные проекты, как JFS, ReiserFS, а также инновационную Tux3, — из-за их хронических проблем с графиком разработки и недостаточной поддержкой кодовой базы. Поэтому они, будучи скорее «мертвыми» чем «живыми», не позволяют рассматривать их как реальные варианты для будущей миграции.
Но перед тем как мы подробно ознакомимся с меню из наиболее перспективных файловых систем ближайшего будущего по версии экспертов Google, попробуем определиться и рассказать, что имеет в виду Google, когда говорит, что мы входим в новую стадию развития ИТ — «Эпоху Больших Данных».
Зетта-наводнение грядёт…
Только в 2008 году было создано около 5 экзабайт уникальной информации. Чтобы разместить такой объем данных, требуется 1 млрд DVD-дисков. Всего три года спустя размер уникальной информации возрос до 1,2 зеттабайта.
Чтобы создать аналогичное количество данных в Твиттере, каждому жителю Земли пришлось бы размещать твиты в течение 100 лет. Если же пересчитать этот объем на размер файла длящегося один час телешоу, то такой видеозаписи хватило бы на непрерывное воспроизведение в течение 125 лет.
Сравнительные цифры
Чтобы более наглядно представить все эти цифры, а также, чтобы немного лучше познакомить читателя с предстоящими необычными единицами измерений информации (пока необычных ему в том смысле, что пока они совершенно не встречаются в его бытовом окружении). Это поможет понять, почему Google так остро озабочен надвигающимся зетта-наводнением, тщательно готовясь к нему уже сегодня.
- На терабайтном жестком диске можно разместить 260 тыс. музыкальных композиций.
- 90 терабайт фотографий пользователи ежемесячно закачивают в Facebook.
- 120 терабайт данных и фотографий произвел телескоп Хаббл за всё время своего существования.
- 500 терабайт информации еженедельно продуцирует Большой адронный коллайдер.
- В 460 терабайт умещаются все данные о погоде, накопленные в Национальном климатическом датацентре (США).
- 530 терабайт новых видеофайлов еженедельно закачивается на YouTube.
- 600 терабайт — таков объем генеалогической базы данных Ancestry.com, записи с 1790-го по 2000-й.
- 1 петабайт данных — именно столько обрабатывают серверы Google каждые 12 минут.
Почувствовали ничтожность своего многогигабайтного жесткого диска по сравнению с подобными «океанами» информации?!
ZFS (Zettabyte File System) — одна из самых известных файловых систем, изначально созданная в Sun Microsystems для операционной системы Solaris, перенос которой на другие платформы вызвало всплеск диаметрально разных эмоций у разработчиков: от бурного восхищения и ликования, до прямо противоположного — раздражения и ярости.
Попробуем ознакомиться с точкой зрения каждой из сторон, а также в причинах существования столь полярных оценок этой файловой системы. Но, прежде чем мы это сделаем, давайте хотя бы в общих чертах ознакомимся с её особенностями и свойствами:
- 128-битнаяфайловая система, что даёт возможность хранения практически неограниченных объёмов информации. На практике это значит, что ZFS теоретически может хранить объёмы информации, которые превышают сегодняшние технологические возможности, при условии использования текущего подхода к организации хранения данных;
- Очень большое внимание уделяется целостности и надежности хранения, как пользовательских данных, так и метаданных ФС, для этого используются продвинутые алгоритмы хэширования;
- Поддержка снапшотов (snapshot) и пулов хранения (storage pools), благодаря чему ZFS сочетает в себе возможности файловой системы и системы управления томами (новая концепция storage-пулов);
- Отсутствие необходимости в fsck благодаря транзакционной природе этой ФС;
- Традиционно считается, что ZFS — это достаточно производительная файловая система. Впрочем, это утверждение иногда ставится под сомнение. Как минимум, конкретные цифры очень сильно зависят от типа задачи, на которой производится подобное сравнительное тестирование производительности;
- Возможности для избирательного сжатия и/или шифрования отдельных файлов или файловых систем;
- Поддержка автоматического распознавания и объединения (исключения) файлов-дубликатов;
- ZFS не поддерживает квоты. Вернее сказать, её поддержка квот несколько своеобразна: понятие «выделение квоты» значит в терминологии ZFS то, что вы ограничиваете размер создаваемой файловой системы. Дизайн системы таков, что каждому пользователю ZFS следует выделять свою собственную файловую систему со всеми сопутствующими ограничениями;
- Определенные проблемы создает не техническая особенность ФС — несовместимая с GPL лицензия на код (CDDL);
- Чтобы показать инновационность ZFS не только в области технических решений, приведу, как пример, возможность управлять основными возможностями ФС через веб-интерфейс;
- И многое-многое другое, так как, повторюсь — ZFS чрезвычайно велик в своих возможностях и особенностях, и перечислить всех их здесь просто не представляется возможным.
Конечно, если смотреть на эти возможности по отдельности, то они во многом не новы и встречаются в том или ином виде в других файловых системах, но такой единый комплекс из приведенных возможностей впервые представлен только в ZFS, что и делает её столь уникальной и интересной на данный момент.
Что касается резко отрицательных откликов на эту, вне всяких сомнений, уже знаменитую файловую систему, то они сводятся в основном к следующим тезисам. Один из ведущих разработчиков Linux, кстати, ответственный за поддержку её дисковой подсистемы, Андрей Мортан (Andrew Morton), разразился гневными обличениями ZFS в «чудовищном нарушении уровней реализации».

В качества ответа на эти выпады, процитирую только ведущего разработчика ZFS Джефа Бонвика (Jeff Bonwick):
«Все эти обвинения в нарушении дизайна уровней реализации файловой системы, оттого, что ZFS комбинирует в себе одновременно функциональность файловой системы, менеджера томов и программного RAID-контроллера. Я полагаю, что ответ на эту претензию будет зависеть от того, что понимать под обвинением „нарушает дизайн уровней“.
В процессе разработки ZFS мы установили, что стандартный дизайн абстрагированных уровней дискового стека провоцирует удивительное количество ненужной сложности и избыточной логики. В процессе рефакторинга мы пришли к мнению, что единственное решение проблемы — это фундаментальный пересмотр границ слоев и их отношений, — что делает все сразу намного более простым».
Какую бы позицию в отношении ZFS не занимали лично вы, следует признать как минимум одно: ZFS — это принципиально новая технология в индустрии файловых систем.
Несмотря на солидных новичков описанных в авангарде, также в список ФС будущего был включен и яркий представитель «старой школы», которым в полной мере является самая прогрессивная ФС 90-ых годов — XFS.
Хотя, нужно сразу отметить, что, несмотря на то, что XFS во многом проигрывает всем трем вышерассмотренным представителям «новой школы» по отдельным решениям, при этом, в общем и целом, XFS смотрится достаточно современно, вполне удовлетворяя потребности индустрии на «сегодня», тогда как вышерассмотренные ФС проектируются уже скорее исходя из вызовов «грядущего завтра».
Следуя уже привычной схеме, приведем её типичные черты, также остановившись и на недостатках, которые отчетливо проступают по мере её использования в современных условиях.
- Реализована поддержка очень больших файлов;
- Не смотря на то, что официально XFS везде позиционируется как настоящая 64-битнаяФС, стратегия дискового драйвера реализована так, что он везде, где это только возможно, избегает использования 64-битногорежима адресации, используя обычную 32-битнуюадресацию, для чего активно используются AGs (allocation group, AG);
- XFS официально — журналируемая файловая система, — но опять же, с той лишь оговоркой, что фиксируются лишь изменения метаданных, включая операции с суперблоком, AGs, inodes, каталогами и свободным пространством. При этом XFS вообще никак не журналирует пользовательские данные;
- Нужно отметить ярко выраженное следствие применения механизма отложенного размещения, о котором мы упомянули выше: его эффективность прямо пропорциональна имеющейся величине оперативной памяти (RAM), что опять-таки очень выгодно при современных тенденциях серверного оборудования;
- Реализация журнала транзакций является самым противоречивым в устройстве XFS, т.к. дизайн таков, что через него проходят все изменения метаданных файловой системы;
- Слабое место XFS — скорость обработки каталогов содержащих большое количество файлов: при таком сочетании условий, сложность реализации алгоритма листинга каталогов приводит к некоторым провалам в производительности этой ФС. В таком случае рекомендуется использование специальной утилиты
xfs_fsrдля оптимизации работы и устранения узких мест в скорости отклика файловой системы.
И всё-таки, несмотря на несколько скептическое отношение к XFS в этом обзоре, следует признать, что у этой ФС есть реальные шансы претендовать на большое будущее.
Как сообщает ведущий разработчик из Red Hat Валери Орорэ (Valerie Aurora), эта крупная компания всерьёз заинтересовалась XFS, пригласив к себе на работу её троих самых активных разработчиков. Так уже в 2010 году RedHat сделала более 70% всех коммитов в драйвер XFS для ядра Linux, а в 2011-2012 годах намерена продолжить серьёзное развитие XFS, для достижения паритета её возможностей с ведущими ФС «новой школы».

Этот же разработчик отмечает, что если дополнительно учесть очень тщательное комментирование XFS (примерно 40% всех строк в исходниках драйвера — это комментарии к коду), то раздувание и усложнение кодовой базы btrfs будет даже ещё большим (против 17% комментариев соответственно).
Hammer — это 64-битная кластерная файловая система построенная на B-деревьях, созданная специально для своего проекта DragonFly BSD известным гуру из FreeBSD Project, — Мэттью Диллоном (Matthew Dillon).
Давайте перечислим основные возможности HAMMER, которые доступны уже на данный момент (или реализация которых близка к завершению):
- HAMMER — это файловая система доступная немедленно даже после падения и перезагрузки системы, здесь нет
fsck; - Размер ФС HAMMER может достигать размера до 1 экзабайта (1 миллиард гигабайтов), и может при этом вмещать в себя до 256 томов, каждый из которых может достигать размера до 4 петабайтов (4096 терабайтов).
- Возможность отката любой дисковой операции и возврата состояния ФС в определенную точку;
- Метод крупнозернистой истории реализуется через мгновенные снимки ФС (снапшоты). По умолчанию, системный крон генерирует один снапшот в день, который хранится в течении 60 дней. Количество и частота снапшотов неограниченна. Все хранимые снапшоты индексируются также посредством B-дерева таким образом, чтобы сделать их хранение на носителях максимально эффективным. Каждый отдельный снапшот полностью отражает состояние файловой системы в заданный промежуток времени. Параллельный метод — мелкозернистой истории, — фиксирует все системные операции в пределах около 20-60 секунд, которые также доступны для отката или повтора (undo/redo options), а также их анализа в случае любого сбоя (мелкозернистая история используется, чтобы избежать избыточных и ресурсоемких операций характерных для снапшотов, при этом, не теряя непрерывного контроля за системой);
- Возможность инкрементального зеркалирования без использования очередей операций, поддержка режима «один master и много slave»;
- Заканчивается тестирование работы в multi-master режиме с распределением данных на несколько хостов сети (резервирование за счет дублирования данных на разные машины). Также реализована поддержка асинхронных транзакций;
- Возможности для создания псевдо-файловой системы (PFS) внутри файловой системы HAMMER. Можно создать до 65535 таких файловых систем. Каждая PFS использует независимое пространство нумерации inode‘ов, что позволяет использовать её в качестве источника или цели репликации;
- Реализована система контроля максимально эффективного распределения пропускной способности канала при выполнении множественного бэкапа ФС (или её PFSs) на её slave-PFSs физически находящиеся на удаленных хостах;
- Поддержка автоматического объединения дубликатов данных на всех PFS (дедупликация);
- Из недостатков — для очистки и реблокинга ФС (pruning/reblocking ops) требуется регулярный запуск специальной сервисной задачи (она выполняется быстро, как правило, в пределах нескольких минут).


Btrfs — это новейшая файловая система, которая в данный момент очень активно развивается, и, несмотря на ещё несколько незрелый вид, уже интегрирована в ядро ОС Linux. В целом, говоря предельно кратко, Btrfs — это файловая система, созданная специально для Linux, основанная на структурах B-деревьев и экстентах, и работающая по принципу «копирование при записи» (copy-on-write).
Мне кажется, что для понимания необходимости создания этой файловой системы, необходимо хотя бы вкратце показать исторический фон, на котором она создавалась. В связи с этим стало уже стереотипным мнением, воспринимать Btrfs как прямой ответ на файловую систему ZFS, которую было запрещено включать в состав ядра Linux из-за лицензионной несовместимости с ним.
Прежде чем привести список основных технических возможностей этой файловой системы, следует ещё раз подчеркнуть, что разработка этой ФС ещё в самом разгаре, и, не смотря на то, что многое уже сделано — многие возможности ещё далеки от совершенства и логического завершения.

Также лишь совсем недавно вновь начал свою работу Git-репозиторий на kernel.org с набором утилит btrfs-progs , ориентированных на управление разделами с файловой системой Btrfs (кстати в новой версии появилась поддержка режима scrub , при котором осуществляется чтение и проверка всех данных и метаданных с целью выявления ошибок и нарушений целостности в файловой системе Btrfs).
Вот её основные особенности:
- Динамическое выделение индексных дескрипторов (динамические иноды,
dynamic inodes). Иначе говоря, в этой ФС нет максимального количества обслуживаемых файлов; - Снимки файловой системы (snapshots), а также возможности делать снимки снимков и записываемые снимки (writeable snapshots);
- Для продвинутого контроля целостности, применяются хеши на все данные и метаданные (тут нужно сразу заметить, так как от сравнения Btrfs и ZFS никак не уйти, что на данный момент в Btrfs применяется CRC-32C, что существенно скромнее, чем в ZFS);
- Очень полезная возможность миграции с традиционных файловых систем ext3/ext4, что дает возможность очень прозрачного перехода на эту новую ФС;
- Завершаются работы над поддержкой автоматического распознавания и объединения дубликатов (дедупликация);
- Проверка файловой системы в рабочем режиме (online) и очень быстрая проверка в нерабочем режиме (offline);
- Прозрачные возможности избирательного сжатия файлов;
- Поддержка режима работы как RAID-массива (одна файловая система на нескольких томах);
- Подтома (subvolumes) и эффективное клонирование файловой системы, быстрое создание инкрементальных архивов;
- Прямая поддержка Device-mapper — важного компонента ядра Linux, с помощью которого организуется расширенное управление логическими томами;
- И многое другое.
И хотя эта ФС пока активно развивается, в качестве иллюстрации точек её будущего роста и масштабности общей задумки, в качестве примера можно привести решение компании Oracle реализовать сетевой протокол новой распределенной файловой системы CRFS (фактически заменяющий устаревшие NFS и CIFS), который будет спроектирован и оптимизирован полностью под btrfs.

Практические выводы
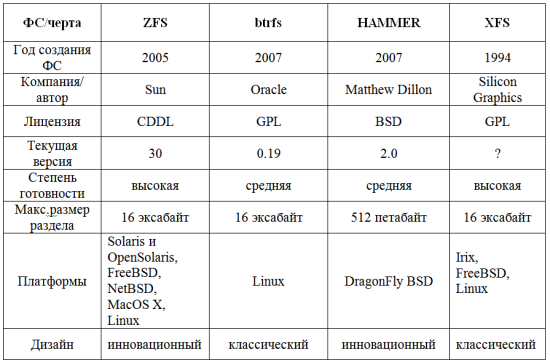
Для удобства, я свел все общие данные о рассмотренных нами ФС в таблицу (см. в конце этого поста).
И нашу практическую часть обзора предлагаю начать с XFS. Эта файловая система очень хорошо масштабируется, она уже сейчас способна оперировать огромными объемами данных. Большая скорость ввода-вывода — это конёк этой файловой системы.
Дополнительным условием эффективности XFS является наличие качественного питания (внезапные отключения достаточно неприятны для неё) и больших объемов оперативной памяти на сервере, что позволяет раскрыть весь потенциал механизма отложенного размещения и прочих «ленивых» техник обильно реализованных в XFS. Сильная многопользовательская нагрузка на хранилище — позволяет продемонстрировать XFS свой инновационный механизм параллельной записи и низкую ресурсоемкость.
Если не считать большой проблемой невозможность уменьшить размер уже созданной ФС — вот, пожалуй, и все узкие места этой надежной и уже проверенной временем файловой системы. Что касается конкретных реализаций, то XFS прекрасно чувствует себя как на Linux, так и на FreeBSD, поэтому выбрать платформу для хранилища здесь есть из чего.
Что же касается ZFS, то первое что приходит на ум, это параноидальное недоверие этой ФС к железу, когда контроль за целостностью данных носит многоуровневый и чрезвычайно изощренный характер. Здесь невольно вспоминается, что на заре SATA, когда первые диски с этим интерфейсом выпускались с большим количеством брака, порождая проклятия особенно со стороны обладателей ext2, разработчиков ZFS на многих конференциях можно было увидеть в майках с мессианской надписью «ZFS любит SATA», как бы подчеркивая этим, что эта ФС способна позаботиться о данных вверенных ей, даже если само «железо» не всегда способствует этому.
ZFS не была включена в ядро Linux из-за патентных ограничений, после чего был собран FUSE-модуль, для поддержки этой ФС в Linux на пользовательском уровне. Конечно, потери скорости и стабильности работы в таком варианте ФС огромны.
ZFS POSIX Layer ).Но, в обоих случаях, несмотря на все озвученные плюсы, ZFS всё-таки не самый сильный выбор для Linux, т.к. вы останетесь с этим выбором наедине, лишенные поддержки со стороны официальных разработчиков ядра, тем более, если учесть скорое пришествие btrfs…
Кстати, о btrfs. Имеет смысл рассматривать эту ФС пока применительно только к ОС Linux (тоже самое можно сказать и о HAMMER к DragonFlyBSD), и можно определенно сказать, что через годик-другой — это будет наиболее универсальный и взвешенный выбор для этой ОС из всех возможных (хотя, стоит почитать интервью с Эдуардом Шишкиным из RedHat, который считает btrfs одним сплошным недоразумением).
fsync тормозище системы с этой ФС просто неописуемые). Но по словам её ведущего разработчика — переход на эту ФС в качестве основной для Linux запланирован уже относительно скоро, на 2013 год.
«Поэтому выбор системы, её режим работы и даже оборудования для её реализации — задача сугубо индивидуальная. При этом, важно всегда смотреть вперед и не забывать про перспективу: ext4 позволяет провести прозрачную миграцию на btrfs, поэтому, мы остановились именно на ней», — объясняет стратегический выбор своей компании Майкл Рубин.